Hi all,
We recently set up a Solaris 11.4 server based on the following hardware;
SuperMicro SSG-6049P-E1CR45L
2x XEON Silver 4114 10 Core 2.2GHz
(LSI 3008 IT mode)
512GB DDR4-2666 ECC RAM
2 x Intel S4600 240GB
2 x Intel Optane 905P 480GB U.2
24 x HGST 10TB SAS
2 x Intel X540T2 10Gbe NIC
Our main storage pool is setup like so;
4 groups of 6 physical 10TB drives in RAID-Z2
1 x Intel Optane 905P 480GB U.2 - cache
1 x Intel Optane 905P 480GB U.2 - log
lz4 compression is enabled on the shared filesystem.
Sharing is via the Solaris CIFS service, sharing to about 32 total clients. Almost all the clients would have only small periods of reading or writing to the server when they save files or do renders, usually files between 500mb - 4GB in size.
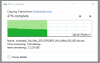
The problem we are having is that Windows clients with SMB have random performance - when it works, the Windows SMB clients will copy files at up to a GB/sec over 10Gbe, usually hovering around 500-700MB/s. The problem is is that at frequent and random times, the copy will just completely stall and drop to 0 bytes/s. It will remain stalled often for a few minutes and then resume, ramping up to the previous speed. Sometimes it will stall again.
These stalls only seem to happen on Windows SMB clients and not macOS clients.
The stalls only seem to happen when writing to the server, not reading from it.
Clients are running Windows 10 1709. Solaris version is 11.4.5.3.0.
I can't see any correspondence to anything happening on the server that would seem to cause this.
If anyone has any thoughts about what might be causing this, it would be greatly appreciated. I can't seem to figure out what might cause this behaviour.
Tristan
We recently set up a Solaris 11.4 server based on the following hardware;
SuperMicro SSG-6049P-E1CR45L
2x XEON Silver 4114 10 Core 2.2GHz
(LSI 3008 IT mode)
512GB DDR4-2666 ECC RAM
2 x Intel S4600 240GB
2 x Intel Optane 905P 480GB U.2
24 x HGST 10TB SAS
2 x Intel X540T2 10Gbe NIC
Our main storage pool is setup like so;
4 groups of 6 physical 10TB drives in RAID-Z2
1 x Intel Optane 905P 480GB U.2 - cache
1 x Intel Optane 905P 480GB U.2 - log
lz4 compression is enabled on the shared filesystem.
Sharing is via the Solaris CIFS service, sharing to about 32 total clients. Almost all the clients would have only small periods of reading or writing to the server when they save files or do renders, usually files between 500mb - 4GB in size.
The problem we are having is that Windows clients with SMB have random performance - when it works, the Windows SMB clients will copy files at up to a GB/sec over 10Gbe, usually hovering around 500-700MB/s. The problem is is that at frequent and random times, the copy will just completely stall and drop to 0 bytes/s. It will remain stalled often for a few minutes and then resume, ramping up to the previous speed. Sometimes it will stall again.
These stalls only seem to happen on Windows SMB clients and not macOS clients.
The stalls only seem to happen when writing to the server, not reading from it.
Clients are running Windows 10 1709. Solaris version is 11.4.5.3.0.
I can't see any correspondence to anything happening on the server that would seem to cause this.
If anyone has any thoughts about what might be causing this, it would be greatly appreciated. I can't seem to figure out what might cause this behaviour.
Tristan
Attachments
-
 32.2 KB Views: 32
32.2 KB Views: 32