ESXi 6.0 NFS with OmniOS Unstable - consistent APD on VM power off
- Thread starter uto
- Start date
Notice: Page may contain affiliate links for which we may earn a small commission through services like Amazon Affiliates or Skimlinks.
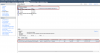
iostat -xn threw and error, doesnt look like the -n switch exists. Here is iostat -xmN zolpool sdb 1 output. Let me know if you want other switches. This is now running on my vSAN all-flash-array datastore.
Attachments
-
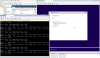 218.2 KB Views: 13
218.2 KB Views: 13
@whitey
U been busy bro")
Pretty sure that it's not Gea's appliance. Once I get my new setup ready (installed new AD + firewall locally on SSD ) I can easily switch off my NappIT without pissing people off.
Will then first try out vanilla OmniOS without Nappit just to prove it's not Napp-IT.
Will be version: Current stable release (r151014, omnios-7648372) cause that seems to been the only version available from OmniOS site.
Like I said may take a while first gotta move away from NFS in order to test more easily (Gea also knows this)
U been busy bro
I'm with you that it SHOULD work..but some how it doesn't dunno what else to say, OmniOS: No, Solaris: Yes (irritating the **** out of me).I KNOW it works on Unix/Illumos as that's ALL I have EVER used in the past so I'm losing my mind here.
Please try Gea's update as well as a stripped/base OmniOS/ZoL config w/ nothing but a headless barebones (JEOS) setup that you can get to try to rule SOMETHING out. Simply replicating my test woule tell us SW/HW issues I'd assume.
Pretty sure that it's not Gea's appliance. Once I get my new setup ready (installed new AD + firewall locally on SSD ) I can easily switch off my NappIT without pissing people off.
Will then first try out vanilla OmniOS without Nappit just to prove it's not Napp-IT.
Will be version: Current stable release (r151014, omnios-7648372) cause that seems to been the only version available from OmniOS site.
Like I said may take a while first gotta move away from NFS in order to test more easily (Gea also knows this)
@whitey
Were you able to get those notes in case I do hit that 'ohh hell no' wall?
Were you able to get those notes in case I do hit that 'ohh hell no' wall?
Haven't been able to do much this week..getting pulled in 5 directions..of course will post progess as info comes along..I will gather my 'ohh hell no' notes up and see if I have any other tidbits of knowledge to share or get you ironed out.
Looking for notes, will reply shortly once I find them. Here is my test of Gea's latest napp-it ova. (napp-it_15c_vm_for_ESXi_5.5u2-6.0.ova (August 18,2015) )
Booted to default BE, NFS seems stable for me even though I did have to manually crank up NFS (couldn't find it in the napp-it interface).
Win10 VM on NFS booted/installed and stable.
Tested iSCSI as you can see also one more level of nested/inception off a autodeployed hypervisor sitting on my base hypervisor cluster mounting back to the napp-it stg appliance iSCSI volume.
No idea good sir, seems HW/env related, dunno what to tell ya abt the 'works in OI/Solaris' Everyone else's config's seem stable.
Booted to default BE, NFS seems stable for me even though I did have to manually crank up NFS (couldn't find it in the napp-it interface).
Win10 VM on NFS booted/installed and stable.
Tested iSCSI as you can see also one more level of nested/inception off a autodeployed hypervisor sitting on my base hypervisor cluster mounting back to the napp-it stg appliance iSCSI volume.
No idea good sir, seems HW/env related, dunno what to tell ya abt the 'works in OI/Solaris' Everyone else's config's seem stable.
Attachments
-
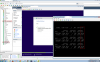 322.5 KB Views: 16
322.5 KB Views: 16 -
 67 KB Views: 15
67 KB Views: 15 -
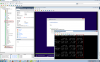 331.7 KB Views: 15
331.7 KB Views: 15 -
 32.1 KB Views: 15
32.1 KB Views: 15 -
 62.6 KB Views: 13
62.6 KB Views: 13
I'm now in the process of building my Microserver to install ESXi/Napp-IT on it or backup purposes. (and to proceed with testing with APD problems that I've had).
I'm going to re-use one of my drives from my 3way mirror and place in my backupserver. (going to create a RAIDZ1 for backup purposes)
What is the correct procedure to remove 1 of my drives from the 3way mirror? (permanently)
ZFS Detach? Offline the drive?
EDIT:
@whitey
Have u tested with the appliance hooked up to an M1015 ? and also truly humbled by your homelab..any articles/pics about this setup floating here or on a blog somewhere..?
I'm going to re-use one of my drives from my 3way mirror and place in my backupserver. (going to create a RAIDZ1 for backup purposes)
What is the correct procedure to remove 1 of my drives from the 3way mirror? (permanently)
ZFS Detach? Offline the drive?
EDIT:
@whitey
Have u tested with the appliance hooked up to an M1015 ? and also truly humbled by your homelab..any articles/pics about this setup floating here or on a blog somewhere..?
Last edited:
If you want to use the removed drive on another machine as a pool you will need to use the zpool split command. If you just want to remove and not use same pool in different machine then you use detach.What is the correct procedure to remove 1 of my drives from the 3way mirror? (permanently)
ZFS Detach? Offline the drive?
Adventures in ZFS: Splitting a Zpool | IT From All Angles
@whitey @gea @nostradamus99 So this is going to get interesting quick. I decided to update from my 840 Pros to some SM843T's today since they showed up yesterday. I snapshotted my SSDs and pushed them to a set of spindles for a second. Shutdown everything and pulled the SSDs after removing them from Omni. Put the new drives in booted back up and moved the data back to the SSDs. I try to boot anything and get the amazing APD that @nostradamus99 has been telling us all long about. I am like I thought I read something about this and yes it could have been a bug in 6.0 But I have now upgrade to 6.0U1 and I still am experiencing the same issue. Next thing to try is pull the drives and see if it fixes it. But I figured I would post this and edit it if I need to.
as of right now I have a stable revision of OmniOS with napp-it running every once in awhile it still kicks a APD but it comes right back. For tonight I am going to leave it that way. Still have to get Crashplan and Sanoid Back functional on this host if I am going to keep it up. But for now things seem stable. Will know more tomorrow.
Still rebuilding my environment..(firewall almost done, SBS 2008 is almost out the door but planning is hard )
Microserver +M1015 is ready and has the latest nappit appliance running haven't tried running any vm's yet.
Release notes for the latest esxi 6.0u1:
VMware vSphere 6.0 Updated 1 Release Notes
)Microserver +M1015 is ready and has the latest nappit appliance running haven't tried running any vm's yet.
Release notes for the latest esxi 6.0u1:
VMware vSphere 6.0 Updated 1 Release Notes
So far just to keep everyone in the loop I had a DIMM of ram fail. I finally checked the BIOS and found it to be D1 for me. Interesting that IPMI and ESXi did not say a peek except into the log files. I would have expected something normally. (I need to find where to query)
That corrupted a windows host and then I snapshotted it. So I had to build a machine out of 3 snapshots to not lose data. But everything so far seems stable.
That corrupted a windows host and then I snapshotted it. So I had to build a machine out of 3 snapshots to not lose data. But everything so far seems stable.
Small update.
Because Gea create a new appliance, I downloaded the latest 0.9f6 appliance.
exported my pool.
shutdown old appliance
removed the datastore from esxi
added the m1015 to the new appliance
started new appliance, configured it
imported the pool
connected nfs datastore
all good..I thought..I wanted to work on my production machine today but by accident logged in my hp microserver and yes..APD:
I rebooted the esxi machine and the datastore was gone..wanted to add it again but after a couple of minutes it came back by itself.. (usually you see the datastore greyed out)
will keep an eye on this server to see if it goes down again..(just have to look at the vobd.log)
If I see that it does go down, I'll try to connect to the nfs share from another linux vm to see what happens. (forgot to do that in the shock that it happened on my new server )
Running esxi version 6.0.0,2809209 with nappit 0.9f6 (latest)
Because Gea create a new appliance, I downloaded the latest 0.9f6 appliance.
exported my pool.
shutdown old appliance
removed the datastore from esxi
added the m1015 to the new appliance
started new appliance, configured it
imported the pool
connected nfs datastore
all good..I thought..I wanted to work on my production machine today but by accident logged in my hp microserver and yes..APD:
Code:
2015-09-30T18:05:00.630Z: [APDCorrelator] 454725050623us: [vob.storage.apd.exit] Device or filesystem with identifier [93b0e02f-35d2f843] has exited the All Paths Down state.
2015-09-30T18:05:00.630Z: [APDCorrelator] 454725050996us: [esx.clear.storage.apd.exit] Device or filesystem with identifier [93b0e02f-35d2f843] has exited the All Paths Down state.
2015-09-30T18:05:00.630Z: [vmfsCorrelator] 454725050876us: [esx.problem.vmfs.nfs.server.restored] 192.168.20.5 /vaultpool01/vmbackup01 93b0e02f-35d2f843-0000-000000000000 vmbackup01
2015-09-30T18:05:13.631Z: [APDCorrelator] 454738051106us: [vob.storage.apd.start] Device or filesystem with identifier [93b0e02f-35d2f843] has entered the All Paths Down state.
2015-09-30T18:05:13.631Z: [APDCorrelator] 454738051328us: [esx.problem.storage.apd.start] Device or filesystem with identifier [93b0e02f-35d2f843] has entered the All Paths Down state.
2015-09-30T18:07:01.631Z: [vmfsCorrelator] 454846051270us: [esx.problem.vmfs.nfs.server.disconnect] 192.168.20.5 /vaultpool01/vmbackup01 93b0e02f-35d2f843-0000-000000000000 vmbackup01
2015-09-30T18:07:33.631Z: [APDCorrelator] 454878051572us: [vob.storage.apd.timeout] Device or filesystem with identifier [93b0e02f-35d2f843] has entered the All Paths Down Timeout state after being in the All Paths Down state for 140 seconds. I/Os will now be fast failed.will keep an eye on this server to see if it goes down again..(just have to look at the vobd.log)
If I see that it does go down, I'll try to connect to the nfs share from another linux vm to see what happens. (forgot to do that in the shock that it happened on my new server )
Running esxi version 6.0.0,2809209 with nappit 0.9f6 (latest)
Last edited:
Gea,
Don't know what to do..even on my new server I'm getting the APD errors so nothing hardware related after all. (I used the new server as a repository for Veeam to do some replication tests so I need NFS for that)
How are you going from appliance to appliance? Do you upgrade your current machine or export and import your pools into a new appliance with the same ip-hostname etc? (Like I've been doing?) maybe there is something there that keeps messing everything up?
My goal was to upgrade once in a while to the newest appliance..new appliance configuring is about 25 min so why not start with a fresh appliance once in while?
Don't know what to do..even on my new server I'm getting the APD errors so nothing hardware related after all. (I used the new server as a repository for Veeam to do some replication tests so I need NFS for that)
How are you going from appliance to appliance? Do you upgrade your current machine or export and import your pools into a new appliance with the same ip-hostname etc? (Like I've been doing?) maybe there is something there that keeps messing everything up?
My goal was to upgrade once in a while to the newest appliance..new appliance configuring is about 25 min so why not start with a fresh appliance once in while?
Well the datastore was up and down most of the day today when I checked the vobd.log.
I then ran a ubuntu iso and installed the nfs client:
$ sudo apt-get update
$ sudo apt-get install nfs-common
$ sudo mkdir /nfs
$ sudo mount -o soft,intr,rsize=8192,wsize=8192 192.168.20.2:/backupdatastore /nfs
$ df -h
I had the console open from vsphere client and then connected the datastore from ubuntu which took a loooong time.
when it did connect I saw my datastore in esxi also come back.
Then triggered an APD by doing a esxcfg-nas -l from an ssh session into ESXi
the nfs datastore at that time was also not available from ubuntu so it's not just esxi that doesn't have access to the datastore anymore.
( I tried creating an directory from ubuntu when the datastore was not available under esxi: )

The NFS-IP is constantly pingable during the "outage" of the nfs datastore
I'll try the update to the latest OmniOS but losing hope for NFS and OmniOS..
I then ran a ubuntu iso and installed the nfs client:
$ sudo apt-get update
$ sudo apt-get install nfs-common
$ sudo mkdir /nfs
$ sudo mount -o soft,intr,rsize=8192,wsize=8192 192.168.20.2:/backupdatastore /nfs
$ df -h
I had the console open from vsphere client and then connected the datastore from ubuntu which took a loooong time.
when it did connect I saw my datastore in esxi also come back.
Then triggered an APD by doing a esxcfg-nas -l from an ssh session into ESXi
the nfs datastore at that time was also not available from ubuntu so it's not just esxi that doesn't have access to the datastore anymore
.( I tried creating an directory from ubuntu when the datastore was not available under esxi: )

The NFS-IP is constantly pingable during the "outage" of the nfs datastore
I'll try the update to the latest OmniOS but losing hope for NFS and OmniOS..
Last edited:
Wow, sorry bro, very frustrating I am sure and I hate to do the poke in the eye but 'I'm rock solid over here'. I think I posted all relevant info in previous post and even spun up ZoL (ubuntu 14 LTS)/napp-it (latest as of a few weeks back and latest omni as well)...freaking strange.Well the datastore was up and down most of the day today when I checked the vobd.log.
I then ran a ubuntu iso and installed the nfs client:
$ sudo apt-get update
$ sudo apt-get install nfs-common
I had the console open from vsphere client and then connected the datastore from ubuntu which took a loooong time.
when it did connect I saw my datastore in esxi also come back.
Then triggered an APD by doing a esxcfg-nas -l from an ssh session into ESXi
the nfs datastore then also was not available from ubuntu so it's not just esxi that doesn't have access to the datastore.
( I tried creating an directory from ubuntu when the datastore was not available under esxi: )
I'll try the update to the latest OmniOS but have lost hope for NFS and OmniOS..
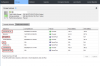
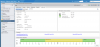
I couldn't live w/out my vSphere/Omni/NFS combo. Even have vSphere VDP configured and crushing down backups to the AIO NFS export off my vSAN datastore just to stress things further. Highlighted in red are NFS datastores mapped to my vSphere 6.0 U1 env.
Attachments
-
 52 KB Views: 25
52 KB Views: 25 -
 103.4 KB Views: 24
103.4 KB Views: 24
Last edited: