Hello!
I obtains this board a couple of days ago and have experienced some problems. Maybe you can point me in a good direction for trouble shooting
")
The board is to be deployed for my SOHO. It is now equipped with a 3950X, 4x32GB Samsung ECC UDIMM and a single SATA SSD (Samsung 863) for evaluation.
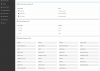
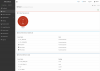
The problem is that at random times get assertions visible in BMC interface, that VCCM is (way!) above threshold. See pic 1. I have not found a general pattern when this occurs, but I have a hunch that is is normally tripped after a POST/Boot... A few minutes after the assertion, the system goes to a complete locked up state. See pic 2. Now the BMC cannot over see/read most of the sensors? Board will also not POST.
What voltage is VCCM? And why does it "jump" to an unreasonable high level?
In order to make sure that it is not the 3950X that is "too much" for the board, I have disabled PBO and Core Boost completely. After doing this, when I stress all CPU cores - it never goes above 55 degrees celsius (no watt meter handy to confirm actual power load). But the assertions does not generally appear to trigger during load, it can equally as well happen after long idle periods.
To get out of the locked state, I at one time left computer powered off over night - no problem for quite a while morning after. At one time I did a BIOS "reload" (upgrade to same firmware version but cleared settings) from BMC - which seemed to fix it atm as well. The board was delivered with FW 3.30 and BMC 1.90.00.
Thanks!
--- EDIT ---
I just had the problem again, while writing this post. Had the system powered down for approx 30 minutes. After power on, it appears to work fine again (until lock up happens next time :-/)... The VCCM reading is now 1.19V and I see that the Critical and Non-recovery levels are set to 1.32 and 1.38 respectively.


 820.8 KB Views: 2
820.8 KB Views: 2