GODDAMN I love it when a plan comes together!
This is gonna be long/ugly...fair warning. :-D
Got the itch to finally peel back the layers of the CEPH onion...pretty darned impressed so far and I KNOW I am JUST scratching the surface.
Started w/ a LOT of RTFM, still have a world of this to do. Since you all know I am a glutton for punishment and pay the mortgage on a Linux skillset I figured I HAD to take the 'from scratch' route and started 'experimenting' w/ a CEPH setup consisting of 1 ceph-admin (headend/node) VM, 3 mon VM's, and 3 OSD VM's w/ the intentions of going to dedicated vt-D setups if this all worked out. Deploy 7 RHEL7 boxes via foreman and 15 mins later I am cooking w/ gasoline.
Flash forward, got CEPH jewell up on that Vm config above and learned quite a bit, needs to dig deeper under the CephFS hood but for now RADOS Block Device is 'DA BOMB' :-D
Phase 2: AKA, Let's get 'froggy'!
Blew up my original CEPH cluster (HAHAH I know lol, some proficient Linux guy right), I had snapshots and I could have beat myself over the head for recovery but it was a 'sandbox' playground. What was my ill demise was trying to add three more vt-D CEPH configured OSD's to the orignal VM 3 node OSD cluster/tree map and BOOM, I did have a different number of disks in the virt v.s. phys but I digress.
Phase 3: OK I need an ACTUAL 'applicable use case'
As a lot of you know I do a lot of my stg protection strategy between two diff vt-D AIO FreeNAS boxes...periodic snapshot/replication schedule is a blessing no surprise there right. But I wanted to dig deeper into this distributed/replicated scale-out storage underpinnings...sure a FreeNAS box is great but you are at the mercy of a single node failure minus HA (which not a lot of us have or have had too much luck implementing on ZFS solutions). CEPH seems to make this interesting to me much in the way that vSAN does, OSD crush map I think I have set to 2 copies, can lose one node effectively...scale OSD's/MON's to hearts content to increase fault tolerant/resilient domains across nodes or increase PAXOS MON quorom/slave/master/CEPH black magic as far as I am concerned until I do more RTFM...I need to do more research here...much to learn.
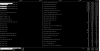
So I have those 3 vt-D CEPH OSD nodes now, one 200gb hussl ssd for journal, 450gb 10K hitachi for XFS formatted data disk...thoughts that come to my mind is I would sure like to see cache/journal stats, saw a 'ceph osd perf' cmd that looked like I saw some throughput/latency characteristics/stats rolling up.
Back to the topic, so far I have setup Veeam Back and Replication 9.5 and hooked that to what I will call my 'CEPH gateway' for now. It's really just a client mounting RBD devices and formatting that XFS, mapping a Veeam backup repo to my CEPH gateway host over ssh, effectively into the CEPH pool, seem to backup at abt 90MB/sec, restore at 250MB/s or so...not too shabby, I smile cause I was on the FreeNAS IRC the other week and saw some sysadmin complaining of Veeam restores pushing some measly 6-9MB/s and taking forever...I only have 6 disks but they seemed performant enough.
Still following? :-D
Next up I had to bite off what I think/hope CephFS addresses. File access like POSIX aware utilities/FS support for NFS/SMB. More research. Figured a brilliant way arnd it though that is working like a champ.
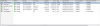
Installed targetcli (LIO framework) on the CEPH gateway RHEL7 box that was also hosting the Veeam backup repo via /dev/rbd0 so I just created another RBD dev and 'rbd create/rbd map' and 'Whitey's your uncle' heh :-D
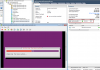
Config targetcli, vsphere, BOOM (lil bit of struggles here but no biggie). Deployed a foreman provisioned ubuntu 16.04 box to the new CEPH iSCSI vSphere VMFS mounted stg. AWESOME!
As a bonus, check this, HOT CEPH filesystem resize for both Linux (rbd/XFS)/vSphere/iSCSI/VMFS)
Post a slew of good pics tomorrow, I need to make sure I captured the end-to-end, I got dang good notes but need to shore up some documentation.
Sorry for the novel, had to decompress somewhere, pretty stoked though, I'm sure my dreams will be crushed 'somewhere' along my battle scarred journey!
This is gonna be long/ugly...fair warning. :-D
Got the itch to finally peel back the layers of the CEPH onion...pretty darned impressed so far and I KNOW I am JUST scratching the surface.
Started w/ a LOT of RTFM, still have a world of this to do. Since you all know I am a glutton for punishment and pay the mortgage on a Linux skillset I figured I HAD to take the 'from scratch' route and started 'experimenting' w/ a CEPH setup consisting of 1 ceph-admin (headend/node) VM, 3 mon VM's, and 3 OSD VM's w/ the intentions of going to dedicated vt-D setups if this all worked out. Deploy 7 RHEL7 boxes via foreman and 15 mins later I am cooking w/ gasoline.
Flash forward, got CEPH jewell up on that Vm config above and learned quite a bit, needs to dig deeper under the CephFS hood but for now RADOS Block Device is 'DA BOMB' :-D
Phase 2: AKA, Let's get 'froggy'!
Blew up my original CEPH cluster (HAHAH I know lol, some proficient Linux guy right), I had snapshots and I could have beat myself over the head for recovery but it was a 'sandbox' playground. What was my ill demise was trying to add three more vt-D CEPH configured OSD's to the orignal VM 3 node OSD cluster/tree map and BOOM, I did have a different number of disks in the virt v.s. phys but I digress.
Phase 3: OK I need an ACTUAL 'applicable use case'
As a lot of you know I do a lot of my stg protection strategy between two diff vt-D AIO FreeNAS boxes...periodic snapshot/replication schedule is a blessing no surprise there right. But I wanted to dig deeper into this distributed/replicated scale-out storage underpinnings...sure a FreeNAS box is great but you are at the mercy of a single node failure minus HA (which not a lot of us have or have had too much luck implementing on ZFS solutions). CEPH seems to make this interesting to me much in the way that vSAN does, OSD crush map I think I have set to 2 copies, can lose one node effectively...scale OSD's/MON's to hearts content to increase fault tolerant/resilient domains across nodes or increase PAXOS MON quorom/slave/master/CEPH black magic as far as I am concerned until I do more RTFM...I need to do more research here...much to learn.
So I have those 3 vt-D CEPH OSD nodes now, one 200gb hussl ssd for journal, 450gb 10K hitachi for XFS formatted data disk...thoughts that come to my mind is I would sure like to see cache/journal stats, saw a 'ceph osd perf' cmd that looked like I saw some throughput/latency characteristics/stats rolling up.
Back to the topic, so far I have setup Veeam Back and Replication 9.5 and hooked that to what I will call my 'CEPH gateway' for now. It's really just a client mounting RBD devices and formatting that XFS, mapping a Veeam backup repo to my CEPH gateway host over ssh, effectively into the CEPH pool, seem to backup at abt 90MB/sec, restore at 250MB/s or so...not too shabby, I smile cause I was on the FreeNAS IRC the other week and saw some sysadmin complaining of Veeam restores pushing some measly 6-9MB/s and taking forever...I only have 6 disks but they seemed performant enough.
Still following? :-D
Next up I had to bite off what I think/hope CephFS addresses. File access like POSIX aware utilities/FS support for NFS/SMB. More research. Figured a brilliant way arnd it though that is working like a champ.
Installed targetcli (LIO framework) on the CEPH gateway RHEL7 box that was also hosting the Veeam backup repo via /dev/rbd0 so I just created another RBD dev and 'rbd create/rbd map' and 'Whitey's your uncle' heh :-D
Config targetcli, vsphere, BOOM (lil bit of struggles here but no biggie). Deployed a foreman provisioned ubuntu 16.04 box to the new CEPH iSCSI vSphere VMFS mounted stg. AWESOME!
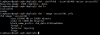
As a bonus, check this, HOT CEPH filesystem resize for both Linux (rbd/XFS)/vSphere/iSCSI/VMFS)
Code:
Linux
rbd --pool=rbd --size=102400 resize veeam
xfs_growfs /mnt/veeam
vSphere
rbd --pool=rbd --size=102400 resize iscsivol01
Use vSphere web client to resize device HOT/live.Sorry for the novel, had to decompress somewhere, pretty stoked though, I'm sure my dreams will be crushed 'somewhere' along my battle scarred journey!
Last edited: