I won auction for 8 1.92tb PM863a drives. They were advertised as "at 70% health". I assumed that would be indicator of TBW.
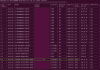
All of them are showing #5 Reallocated Sector Count non zero values. I assume that's all right for those drives as they are in the ballpark of 20-50 and #180 Unused Reserved Block Count is ~6400 so plenty to spare here for few years (of course if this number will not rise rocket speed).
But three of them are showing #187 Uncorrectable Error Count somewhere around ~20, also #195 ECC Error Rate is same value for each drive (ie: #187 is 20, #195 is also 20).
GSmartControl is showing that these drives are in pre-fail state, it's showing errors in error log, red numbers etc...
So I used official software DC Toolkit from samsung as this is specifically for PM863(a) (and other) drives.
DC Toolkit is showing that these drives are in good health.
I ran extended offline check for every one of them, result is "Completed without error", multiple times.
I did some research and badblocks will not help me here to determine state.
Screenshots attached.
One drive did cost 46 euros including shipping, that's why I'm hesitant on returning them")
I don't know what to do. Maybe you guys will have more insight on this and help me to decide?
All of them are showing #5 Reallocated Sector Count non zero values. I assume that's all right for those drives as they are in the ballpark of 20-50 and #180 Unused Reserved Block Count is ~6400 so plenty to spare here for few years (of course if this number will not rise rocket speed).
But three of them are showing #187 Uncorrectable Error Count somewhere around ~20, also #195 ECC Error Rate is same value for each drive (ie: #187 is 20, #195 is also 20).
GSmartControl is showing that these drives are in pre-fail state, it's showing errors in error log, red numbers etc...
So I used official software DC Toolkit from samsung as this is specifically for PM863(a) (and other) drives.
DC Toolkit is showing that these drives are in good health.
I ran extended offline check for every one of them, result is "Completed without error", multiple times.
I did some research and badblocks will not help me here to determine state.
Screenshots attached.
One drive did cost 46 euros including shipping, that's why I'm hesitant on returning them
I don't know what to do. Maybe you guys will have more insight on this and help me to decide?
Attachments
-
 163.5 KB Views: 21
163.5 KB Views: 21 -
 172.3 KB Views: 21
172.3 KB Views: 21 -
 43.9 KB Views: 15
43.9 KB Views: 15