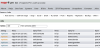
I have 4x 2.5” backup HDD, which I split into 2 pairs. I rotate a pair from the server with a pair offsite.
I would like some help on Keep/Hold settings, to ensure there is always a snap pair for replication.
I would like to just keep 2 replication snaps on the Target pools (as default, in case of problem with current snap); but keep 20 snaps on the source to allow for up to 20 replications on the second set of back up drives without losing the snap pair of the first set.
My process:
- Using Napp-it, I set up a number of replication jobs for half my filesystems to pool B1 on one drive; and the other half to pool B2 on the other drive.
- Export the pools and remove the drives.
- Plug in the other pair of drives and Import with the same pool names B1 and B2.
- Run the replication jobs again on the second pair with the same pool names B1 and B2.
The filesystem replication jobs use either [-i] or [-I] depending on whether I need to keep all intermediate snaps. I don't have the backup space for all intermediate snaps on some filesystems, where I frequently delete old data.
This seemed to work fine for a while until I seem to have accidentally exceeded the keep/hold of the snap pairs and so only the first pair of drives could do an incremental replication, and the other pair now needs to re-do a full replication as its snap pair no longer exists on the source.
I need to adjust the Keep / Hold settings, so I don’t lose the source snaps if I leave it too long, or replicate too many times on the same pair of drives without rotating to the offsite drives. When I create a replication job with Napp-it, there are options to Keep and Hold 'Target' snaps, which would be my back-up drives. What is happening to the 'Source' snaps, are they automatically the same as the target snap settings?
So if I set, eg:
- Keep: [hours:24,days:32,months:12,years:1], the target pool would keep its replication snaps for up to a year, but I don't know if it knows which one to keep as I would need to keep a snap pair for both sets of drives.
- Hold: [20s], the target pool would hold 20 snaps. Is the source pool also retaining 20 snaps? If so, I understand I would need to do 20 replications on one set of drives before the last snap used by the offsite drive is deleted. For filesystems with the replication option [-i] and Hold:20s, does this mean the backup target is storing previously deleted data contained in the 20 older replication snaps? if so, I might not have the space if I delete a huge amount.
Edit: I can't get this to work at all now, perhaps this was never supposed to work.
- On my first set of drives, I added option Hold:20s to the existing replication jobs, and ran them all successfully.
- On my second set of drives, I destroyed all filesystems, as the jobs could no longer find a snap pair (as noted above), I then ran the same replication jobs successfully
- I exported the second set and imported the first set to test another replication, and they are all failing to replicate, as they can no longer find a snap pair (error my_log end 1551: job-repli, source-dest snap-pair 3 not found)
I would like some help on Keep/Hold settings, to ensure there is always a snap pair for replication.
I would like to just keep 2 replication snaps on the Target pools (as default, in case of problem with current snap); but keep 20 snaps on the source to allow for up to 20 replications on the second set of back up drives without losing the snap pair of the first set.
My process:
- Using Napp-it, I set up a number of replication jobs for half my filesystems to pool B1 on one drive; and the other half to pool B2 on the other drive.
- Export the pools and remove the drives.
- Plug in the other pair of drives and Import with the same pool names B1 and B2.
- Run the replication jobs again on the second pair with the same pool names B1 and B2.
The filesystem replication jobs use either [-i] or [-I] depending on whether I need to keep all intermediate snaps. I don't have the backup space for all intermediate snaps on some filesystems, where I frequently delete old data.
This seemed to work fine for a while until I seem to have accidentally exceeded the keep/hold of the snap pairs and so only the first pair of drives could do an incremental replication, and the other pair now needs to re-do a full replication as its snap pair no longer exists on the source.
I need to adjust the Keep / Hold settings, so I don’t lose the source snaps if I leave it too long, or replicate too many times on the same pair of drives without rotating to the offsite drives. When I create a replication job with Napp-it, there are options to Keep and Hold 'Target' snaps, which would be my back-up drives. What is happening to the 'Source' snaps, are they automatically the same as the target snap settings?
So if I set, eg:
- Keep: [hours:24,days:32,months:12,years:1], the target pool would keep its replication snaps for up to a year, but I don't know if it knows which one to keep as I would need to keep a snap pair for both sets of drives.
- Hold: [20s], the target pool would hold 20 snaps. Is the source pool also retaining 20 snaps? If so, I understand I would need to do 20 replications on one set of drives before the last snap used by the offsite drive is deleted. For filesystems with the replication option [-i] and Hold:20s, does this mean the backup target is storing previously deleted data contained in the 20 older replication snaps? if so, I might not have the space if I delete a huge amount.
Edit: I can't get this to work at all now, perhaps this was never supposed to work.
- On my first set of drives, I added option Hold:20s to the existing replication jobs, and ran them all successfully.
- On my second set of drives, I destroyed all filesystems, as the jobs could no longer find a snap pair (as noted above), I then ran the same replication jobs successfully
- I exported the second set and imported the first set to test another replication, and they are all failing to replicate, as they can no longer find a snap pair (error my_log end 1551: job-repli, source-dest snap-pair 3 not found)
Last edited: