The time is different. Back then the throughput of cores are way smaller, so it can get away with having slower memory. Also most applications can't use more than two cores, so the extra cores are mostly decorations anyway.
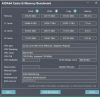
Now CPU core sections, with way more cores and way wider architecture and FP units, are hundreds of times more powerful than core 2 duo, but DDR4 is only less than 4 times the bandwith that of DDR2, and the latency improvements are even more minimal. That is the problem. Actually I think intel has the right to bad mouth about AMD's MCM solution. It's very primitive with no advanced packaging, and the use of SerDes design which means the loaded latency can sky rocket. The end result, for example, in realworld rendering scenario below, a 64-core 7B13 does not have any real advantage against a 32-core 8375C. This is even the advertised app AMD put up on their presentations, some other apps like modeling and sculpting are even worse, considered unusable by some designers here. In recent months the prices of 3rd gen Xeon models went up a lot here, some models like 8375c became hard to come by. Think that is the reason.
View attachment 25331
BTW the PTS link, still working on EPYC3, it refuses to run on the older ubuntu version I used test other CPUs. There is an overall score you can select to show.
 235.5 KB Views: 73
235.5 KB Views: 73 600.3 KB Views: 78
600.3 KB Views: 78 379.9 KB Views: 78
379.9 KB Views: 78