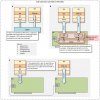
Hello, long time lurker, first time posting. A long time user and fan of virtualization and VMware (since circa 1999) and have been consolidating my home infrastructure since (in addition to every company I have worked with).
I am interested in any information with respect to VM-to-VM network performance on the same physical ESXi box; in particular:
a) VM-to-VM using ESXi vswitch.
b) VM-to-VM using an SR-IOV-capable NIC with an eswtich.
Specifically, does an SR-IOV-capable NIC with an eswitch (e.g., Intel, QLogic or Mellanox):
a) Significantly reduce CPU overhead for VM-to-VM network traffic on the same box?
b) Is the VM-to-VM data rate limited by the NIC PHY?
I'm asking because I'm working on a new home consolidation build, but don't want to spend $500-700 if it doesn't buy more than simply buying more cores.
Thanks in advance.
I am interested in any information with respect to VM-to-VM network performance on the same physical ESXi box; in particular:
a) VM-to-VM using ESXi vswitch.
b) VM-to-VM using an SR-IOV-capable NIC with an eswtich.
Specifically, does an SR-IOV-capable NIC with an eswitch (e.g., Intel, QLogic or Mellanox):
a) Significantly reduce CPU overhead for VM-to-VM network traffic on the same box?
b) Is the VM-to-VM data rate limited by the NIC PHY?
I'm asking because I'm working on a new home consolidation build, but don't want to spend $500-700 if it doesn't buy more than simply buying more cores.
Thanks in advance.
")