Hello,
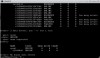
I noticed my file server acting really slow last few weeks but was too busy to investigate until now. Even napp-it would not be able to pull Napp-it would not even be able to retrieve anything from the Disks or Pools sections. It would keep loading and loading, even hour later. Finally, I remembered to ssh in to OmniOS directly and type "zpool status". I have attached my results. I'm running
OmniOS v11 r151022, the 10x 3TB drives are connected to two HBA LSI 9211-8i cards.
I have the pool set to have 2 spares. Now I am worried, from the screenshot does it seem 4 drives are bad or just the 2 faulted drives? What exactly should I do next? Replace all 4 drives or just the 2 faulted or degraded ones? Right now thinking to back up important data to few spare USB external drives I have and then focus on troubleshooting/fixing the pool. Appreciate any help please!
Thank you!
I noticed my file server acting really slow last few weeks but was too busy to investigate until now. Even napp-it would not be able to pull Napp-it would not even be able to retrieve anything from the Disks or Pools sections. It would keep loading and loading, even hour later. Finally, I remembered to ssh in to OmniOS directly and type "zpool status". I have attached my results. I'm running
OmniOS v11 r151022, the 10x 3TB drives are connected to two HBA LSI 9211-8i cards.
I have the pool set to have 2 spares. Now I am worried, from the screenshot does it seem 4 drives are bad or just the 2 faulted drives? What exactly should I do next? Replace all 4 drives or just the 2 faulted or degraded ones? Right now thinking to back up important data to few spare USB external drives I have and then focus on troubleshooting/fixing the pool. Appreciate any help please!
Thank you!
Attachments
-
 164.5 KB Views: 42
164.5 KB Views: 42
Last edited:



")