So I am in the process of putting a new 2011 v3 system with 2x e5-2686 v3. Will post some more pics later. everything still out of case at this time. only have 1 cpu and 32GB for now, only using the onboard video, testing everything to make sure it's all good.
So I am in the process of putting a new 2011 v3 system with 2x e5-2686 v3. Will post some more pics later. everything still out of case at this time. only have 1 cpu and 32GB for now, only using the onboard video, testing everything to make sure it's all good. These components will replace the stuffs in one of my 2011 v1 system..
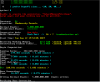
So far using 1 cpu, it's about 4x faster than my i7-2600k at calculating pi using y-cruncher. so with 2x cpu will be 8x faster.... thats about what i expected since my old dual e5-2670 was about 4-5 x faster than the i7-2600k..
also will upgrade my other 2011 system with 2x e5-2696 v2 when cpu gets here soon. it's going to be a busy month...lol..
Last edited: